SEO Authorities and their opinions
NOTE: Besides making a list of some notable quotes written by authorities, I'd also want to make a list of quotes where authorities were CLEARLY WRONG, just as a reminder that anyone in the SEO field can be wrong, and to be careful about trusting any one source.
Black Hat SEO Techniques
I'm going to do a bit of homework on the dark side of SEO to satisfy my curiosity and to know all the methods available to an SEO and to clarify what pitfalls to avoid. More I read, I'm surprised to find some nuggets of info a white hat can use. Here's an interesting comment on SEO by Irishwonder.
Bottom Fishing
"Bottom fishing is going to the bottom of the barrel looking for the keywords that are only going to score 10,20, maybe 500 hits a month." Basically, have each page target one keyword and generate 1000,000 pages.
Guest Books & Blog Comments
Black hats use these to build inbound links to their fresh sites, and plop a spam site on a subdomain on free hosting.
Multiple Domains a Day
Black hats put in 2 hours to set up a site and release 3-4 domains a day or more to flood the SE.
RSS/blog submission software
Free hosting for black hat use
What Tea Bag Earl does to whip up a website
-----------------------------------------------------------------------------
Back to White Hat SEO
DICEE - An article about blogging useful for linkbaiting, etc. But I found it useful for rethinking my strategy with my own sites. DICEE stands for "deep","indulgent","complete","elegant","emotive." Not really directly SEO related, but still, it's something to keep in mind when developing any website.
DUPLICATE CONTENT
- Do a wordcount on pages. Filesize may be less important than actual number of words on a page.
- Use absolute links since they don’t usually get re-written by scrapers.
Other SEO Links
- SEOMOZ SEO Ranking Factors
- PR extraction code discussed at Digital Point.
Interesting SEO Quotes
Bill Slawski
It can be tempting to relate number of links to a page with the number of valuable links to a page, but a page on a site linked to by the three most important pages on a site may be more important than another page linked to by hundreds of other pages.
Todd Malicoat (on outbound links to other authority sites)
While relationships are important the actual ANCHOR TEXT is extremely important as well. Linking to documents with the anchor text of the phrases you are targeting for a specific page is quite helpful (though it may negatively impact visitor retention rate).
Jill Whalen (Alt tags)
Very important for clickable images. Not so much for non-clickable ones.
Scottie Claiborne
Only in images that are links. Images that are not links typically show no change when adding alt text however for link images, it replaces the anchor text and as such, is very important.
Note: This is worth testing.
Scottie Claiborne
If it plays a role in ranking for misspellings, than it plays a role, period. You can't say it works for misspelled words but not for others. Personally, I don't believe it works for misspellings. I believe Google's habit of suggesting a correction for a misspelling or semantic analysis is more likely to be the source of "misspelled" traffic than including the misspellings in the meta keywords tag.
Note: Another thing I'd like to test. Put a misspelled keyword in the meta and see if it does anything at all.
Michael Martinez
H1 and BOLD are still vital indicators of important factors
Bill Slawski
Persistent internal links do have the potential to make a page appear relevant for a particular query, especially if there is a correlation between the anchor text within those and such things as page titles, and words upon the pages.
Dan Thies (On incoming links from domains on the same IP/C block)
assuming we ignore the tremendous value of internal links within a site, and pretend that there's something wrong with having >1 domain
2K (regarding location of link "on the page"
not valid question at the moment... should be "location of link in code"
Ammon Johns
Block level analysis, or indications that a link is in the footer will devalue the link considerably.
Dan Thies
beyond the obvious, overuse of noindex (instead of robots.txt) can be as bad as duplicate content - picture the spider fetching 500 pages and finding a noindex on 400 of them - you think they'll be back for the other 10,000 on the site?
I don't agree with Dan. I'd like to run some tests to see if overuse of noindex is scorned by SEs.
This user profile specific advertisement patent (PDF) seems to suggest Google ignores <P> with length less than minpagelength and pulls a text snippet of length N from document paragraphs: Note that the patent is dated 2002, and the procedure described below has to do with identifying user specific interests, not how Google ranks a document in their SERPS.
- "Select the first N words (or M sentences) from each paragraph of length>=MinParagraphLength" (example given: 100 words, 5 sentences)
- To reduce computational and storage load, maximum limit of 1000 words may be imposed on the sampled content from each document.
- In one embodiment, the paragraph sampling procedure organizes all the paragraphs in a document in length decreasing order, and then starts the sampling process with the paragraph of maximum length.
- The beginning and end of a paragraph depends on the appearance of the paragraph in a browser...for this reason, certain HTML commands e.g. bold and HREF are ignored when determining paragraph boundaries.
- (optional) Add the document title to the sampled content, if the length of sampled content < a predefined threshold.
- (optional) Add the non-inline HREF links to the sampled content, if the sampled content < a predefined threshold.
- (optional) Add the alt tags to the sampled content, if the length of sampled content < a predefined threshold.
- (optional) Add the meta tags to the sampled content, if the length of sampled content < a predefined threshold.
Another interesting document VARIABLE LENGTH SNIPPET GENERATION patent: This patent explains how Google returns snippets with their search results. The length depends on "how much of a document a user might need before identifying the document as one of interest."
- the generating comprises setting the length of the snippet as a function of the document age.
- Lower the query score, longer the snippet length (more info is needed for a user to determine if the document is what the user is looking for).
- Ways of determining a document's age:
- Creation date
- Last modified
- Date provided by host
- Date field on a document
Another patent describes how Google looks not only for phrases in the document but the presence of related phrases. How are related phrases indentified? Google Adwords Keyword Tool may be a good source of finding "related phrases" when writing a copy about a specific keyword? Nope. A search for "Desirae" for example doesn't display "naughty at home." The lack of related phrases may result in a page ranking lower.
- " The system is further adapted to identify phrases that are related to each other, based on a phrase's ability to predict the presence of other phrases in a document."
- "Two phrases are related where the prediction measure exceeds a predetermined threshold."
- Identifying Duplicates: " An information retrieval system may also use the phrase information to identify and eliminate duplicate documents, either while indexing (crawling) the document collection, or when processing a search query. For a given document, each sentence of the document has a count of how many related phrases are present in the sentence. The sentences of document can be ranked by this count, and a number of the top ranking sentences (e.g., five sentences) are selected to form a document description. This description is then stored in association with the document, for example as a string or a hash of the sentences. During indexing, a newly crawled document is processed in the same manner to generate the document description. The new document description can be matched (e.g., hashed) against previous document descriptions, and if a match is found, then the new document is a duplicate. Similarly, during preparation of the results of a search query, the documents in the search result set can be processed to eliminate duplicates."
-
This leads me to believe that keeping the description snippet in the SERPS unique during indexing AND during search is key in avoiding "similar pages" filter and duplicate pages penalty.
- Even if the description returned with site: are unique, if a specific search for keyword returns identical description snippets, then the pages with identical description snippets will vanish into "similar pages" and in the worst case, flagged as duplicates.
- Since its inevitable with a site with navigation, that certain queries will return identical description snippets, I doubt this will throw a document into the supplementals.
- Which means this: Any description snippet returned by a search query for a target keyword must be unique across a site.
- The first sentence that appears seems to be the first occurance of keywords in the HTML.
- I'm not sure if the duplicates found during a search is a reason for worry, if the pages are indexed correctly as unique documents.
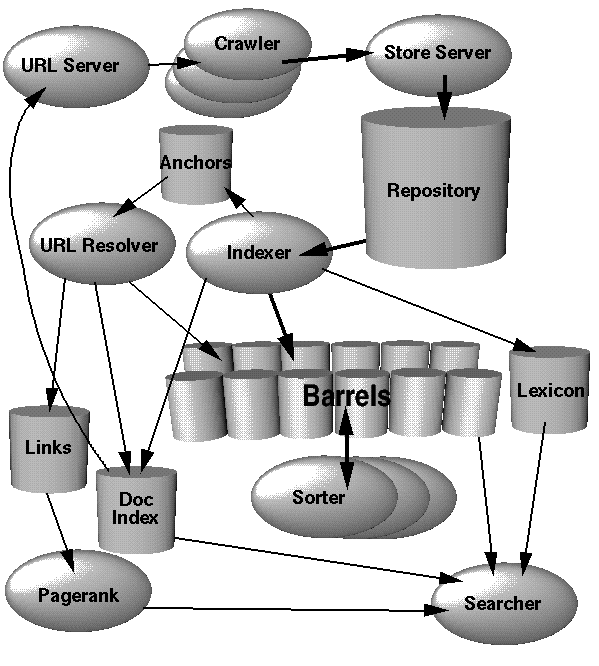
This article talks about Google assigning a unique DocID to each webpage (note Matt Cutts claims Google's done away with DocID's long time ago). The subject was brought up by one of WMW members during the latest supplemental problems. It also sites d (PR dampening factor) as 0.85. Few other observations:
One thing GoogleGuy said during 3/1/2005 supplemental mess is "I'm asking the crawl/index guys to check out" which doesn't tell me much, but it might be a clue.
I won't quote any more blocks of text from this patent to avoid duplicate content problems, but there are more interesting info in this document that makes me wonder:
- If the cache is a DB table with DocID as primary index, I would assume that DocID is auto-incremented. Doesn't that make it more difficult to "deindex" something, since that creates a gap in the DocIDs? And would it not be more convenient if Google saved that record even if it 404ed to avoid reinserting the url using a new DocID? This would minimize DocID being incremented needlessly.
- "The current lexicon contains 14 million words "
- "A hit list corresponds to a list of occurrences of a particular word in a particular document including position, font, and capitalization information." What about things like H1?
- "Fancy hits include hits occurring in a URL, title, anchor text, or meta tag."
- "A plain hit consists of a capitalization bit, font size, and 12 bits of word position in a document (all positions higher than 4095 are labeled 4096)." Word position probably means if a word is the 5th word in a block of text, word position = 5. This may also mean that if a page is too big, then any word beyond 4095th word will be in the same position.
- "Font size is represented relative to the rest of the document using three bits"
- "A fancy hit consists of a capitalization bit, the font size set to 7 to indicate it is a fancy hit, 4 bits to encode the type of fancy hit, and 8 bits of position." This sounds like font size is irrelevant if the text occurs in URL, Title, anchor text, or meta tag...which makes sense. 4 bits used for type also makes sense. So Google is built to value words in URL, title, anchor text, and meta tags...until the day they restructure their database?
- "For anchor hits, the 8 bits of position are split into 4 bits for position in anchor and 4 bits for a hash of the docID the anchor occurs in. "
- n important issue is in what order the docID's should appear in the doclist. (doclist is a list of documents that has hits for a particular wordID). One simple solution is to store them sorted by docID. This allows for quick merging of different doclists for multiple word queries. (I guess a simple JOIN). Another option is to store them sorted by a ranking of the occurrence of the word in each document. This makes answering one word queries trivial and makes it likely that the answers to multiple word queries are near the start. However, merging is much more difficult. Also, this makes development much more difficult in that a change to the ranking function requires a rebuild of the index. We chose a compromise between these options, keeping two sets of inverted barrels -- one set for hit lists which include title or anchor hits and another set for all hit lists. This way, we check the first set of barrels first and if there are not enough matches within those barrels we check the larger ones.
- "Every hitlist includes position, font, and capitalization information. Additionally, we factor in hits from anchor text and the PageRank of the document. ". What is this Capitalization information? Are words given more weight if its CAPITALIZED?
- "We designed our ranking function so that no particular factor can have too much influence. "
- "Google counts the number of hits of each type in the hit list. Then every count is converted into a count-weight. Count-weights increase linearly with counts at first but quickly taper off so that more than a certain count will not help. "
- "We take the dot product of the vector of count-weights with the vector of type-weights to compute an IR score for the document. Finally, the IR score is combined with PageRank to give a final rank to the document. "
- For 2+ word queries: "Now multiple hit lists must be scanned through at once so that hits occurring close together in a document are weighted higher than hits occurring far apart. The hits from the multiple hit lists are matched up so that nearby hits are matched together. For every matched set of hits, a proximity is computed. The proximity is based on how far apart the hits are in the document (or anchor) but is classified into 10 different value "bins" ranging from a phrase match to "not even close". Counts are computed not only for every type of hit but for every type and proximity. Every type and proximity pair has a type-prox-weight. The counts are converted into count-weights and we take the dot product of the count-weights and the type-prox-weights to compute an IR score."
- "Notice that there is no title for the first result. This is because it was not crawled. Instead, Google relied on anchor text to determine this was a good answer to the query."
- So from their illustration, here are some of the basic factors:
- Proximity of words "bill clinton"
- PageRank
- Anchor text
- Proximity suggests that exact order of words are irrelevant.
- As for link text, we are experimenting with using text surrounding links in addition to the link text itself.
Yahoo Site Explorer
Interesting quote of Yahoo representitive in NYC SES Conference about Yahoo Site Explorer:
Audience Question: This is for Google and Yahoo: My site has over 500,000 products. What is the difference in the number of pages crawled and the number of mentions? For Yahoo we only have 500 results. Why is there a difference?
Yahoo: Use the Site Explorer tool. If Site Explorer only shows 500 pages, then there is an issue.
Google: Every search engine crawls in a different way. Mentions vs indexed. There are instances where we know about the url, but we did not crawl it. Your site may not have enough PageRank for us to do a deep crawl.
Yahoo: The site explorer offers an option to provide a RSS feed of your site's urls.
Another interesting snippet:
Google: Gives example of how Alexa toolbar has been spoofed and used to spam Matt's "related sites" info on the Alexa listing for his blog. (tempting :D )
Audience Question: Is there any truth that search engines ignore robots.txt?
MSN: No, we comply. I found it amusing that Google and Yahoo did not reply here. I know from experience that at least Google occassionally index urls despite robots.txt.
Yahoo: If urls are repeated in different (sitemap) RSS feeds they will just be revisited. Do I sense a loophole / possible exploit here?
Google: The only thing we don't support is crawl delay. Many webmasters that used that parameter incorrectly.
MSN: Regarding links: Links that look natural, that provide value are the ones we use.
Google: Matt shows his Google Sitemap data using then new version of sitemaps. For some reason Matt's blog is #2 for a phrase like free porn on Google local.
Yahoo Answers
I'm not sure how this can be used in SEO. From what I see, the included urls are unlinked text. Do Yahoo give more weight in SERPS if a website is mentioned in an answer?
MSN Sitemap RSS
How do I do it?
Copyright SEO 4 fun