Supplemental Results Detector Tool (a.k.a. PageRankBot)
Heads Up: This tool is no longer free.
Download (Content first, yapping second - good policy don't you think?)
The best (and only) supplemental results analyzing tool on the planet now available in Java. Whether you're an SEO or a webmaster, you can use this tool to make sure your most important pages are listed in Google's main index. Reviewed by a handful of high-profile players in the SEO industry including Aaron Wall, Andy Beard, Dan Thies, Red Cardinal (who helped me BETA test the tool), and Rustybrick over on Search Engine Land.
HEADS UP
(June 17, 2009) Matt Cutts recently announced that PageRank blocked by nofollow "evaporates." There's a relatively safe workaround using Javascript. I updated this tool to accurately reflect that change. That said, keep in mind when I built this tool, the nofollow hack was still effective - just see the screenshot below for proof. The same effect can still be achieved using javascript.
Looking for a way to detect which pages on your site are supplemental?
This tool isn't it. This tool is better than that. It gives you complete control over internal link structure and PageRank distribution, which is all you need to solve supplemental results issues (as long as you have enough backlinks pointing at your site, of course).
What this tool will do for you:
- Gives you complete control over internal PageRank distribution.
- Helps you visualize exactly what's going on with your internal links.
- Takes the guesswork out of solving supplemental results issues.
- Saves your work so you only have to deep crawl a site once.
- And a whole lot more.
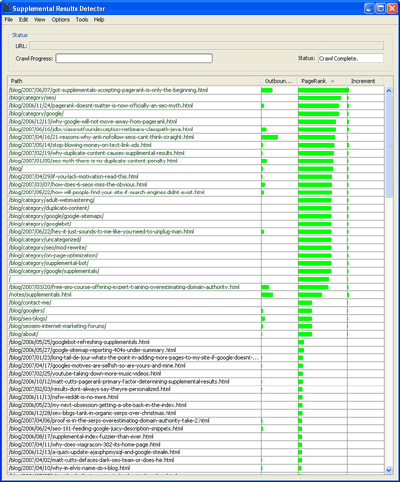

(Compare the highest PageRank page reported by Webmaster Tools with the Supplemental Results Detector results. I intentionally shifted PageRank to one of my recent posts and prevented the blog home page from hogging PageRank. See, with this tool, you have complete control over internal PageRank distribution, which is one of the key tactics for combatting supplemental results issues.)
And guess what? Even a caveman can install it.
Just follow these simple directions:
Install JDK and MYSQL.
- Download / updated to Java Runtime Environment (JRE) 6 Update 2. If you see a "Could not find the main class. Program will exit." error, then you need to update.
- Download and install MYSQL 5 (Community Server).
Configure your MYSQL server.
- Go to Start > MYSQL > MYSQL Server 5.0 > MYSQL Server Instance Config Wizard.
- Follow the directions.
Download and install the application.
Go here to download, which requires email validation.
Configure MYSQL information.
- The application will ask for MYSQL information. Java Derby options will appear as well, but ignore them. The only option that actually works is MYSQL.
- The default host and port are localhost:3306. You don't need to change them.
- Type in a database name. If it doesn't exist, it will create it.
- Type in username and password.
- Click "Test Connection" to make sure the application can connect to your MYSQL server. The application will not run if configuration fails to establish a connection.
- If the application fails to start after configuring MYSQL, then most likely the MYSQL info you entered wasn't on the dot. Delete the config file, re-enter the MYSQL info, click "Test Connection" to make sure a connection is established.
Analyzing a Domain
- Go to File > Enter Domain URL.
- Type in your domain URL.
- Choose Selective Crawl.
- Click Run.
That's it.
Got problems?
Solutions to most installation issues are covered in the PageRankBot Troubleshooting Guide.
Features
- Parses robots.txt.
- Follows 301 redirects to pass juice to the right URL.
- Obeys META NOINDEx,NOFOLLOW
- Saves information in MYSQL.
- Handles relative URLs (e.g. .../../home.html)
- Uses multiple threads for faster crawling
- Tested sites up to 14,000 pages.
Additional Features
- CSV Export - A domain's url data can be exported to a CSV file, so you can play with the data in Excel.
- Crawl a domain from any entry point, not just the root URL. Useful if you don't want to start crawl from root or if you want to test internal link strategies in a subdirectory sandbox.
- Simulates dangling pages (dead end pages with no outbounds) by redistributing their PageRank to the rest of the web.
- Robots.txt disallowed URLs accumulate PageRank, though since links on the pages can't be crawled, these pages are treated as dangling pages.
- META noindexed URLs accumulates PageRank if links point at them.
- META nofollow creates dangling pages. So a META noindex,nofollow page will accumulate PageRank and then bleed that PageRank to the rest of the web instead of circulating it back into other pages of a website.
- REL=nofollow is treated like an outbound link. Previously, nofollows were thought to push their PageRanks to followed links on the same page, but now Google states that is no longer the case.
- TBPR scraping - The tool can be used to scrape TBPR. While the TBPRs are inaccurate, they can be used to give you a sense of the health of a domain. For example, a well-linked-to domain will have a larger number of pages with some green than a poorly-linked-to domain. The total TBPRs combined also can be used to gauge depth of index penetration. TBPR of a specific page can also be a hint to its supplemental status.
- Google Cache date scraping - this tool can be used to scrape Google cache dates en masse using multiple proxies. While cache dates are inaccurate, they are decent metrics for deciding which page to optimize first, the overall link popularity of a domain, and can hint at a page's supplemental status. Since there's a limit to the number of pages Googlebot will crawl per day (depending on a site's total PageRank), you can gauge a site's link weight by counting the number of pages with cache dates fresher than 1 week. At the same time, crawl limit introduces inaccuracies because even if a site has 2000 TBPR 6 pages, if the site only gets crawled 20 pages/day, those pages will not all have the same cache dates. So in that sense, cache dates are not exactly the next TBPR. A site's update frequency also can influence cache freshness.
- Calculates PageRank using the original formula. PageRank calculations have evolved over the years, so using any variation of known PageRank formulas are only approximations. For example, links higher up on a page may carry more weight than links positioned way down on the bottom.
- Shows you Disallowed and Noindexed urls. Debugging crawling errors is fundamental aspect of SEO. SRD tool shows you which urls are disallowed and noindexed, how much PageRank the urls are bleeding, which pages link in to these pages, and more.
- Records Status Codes. You can use SRD to check for broken links. Links to multimedia etc will not be checked, however.
Limitations
- Crawling can be slow, depending on the domain you're crawling. It may take a while spidering a 10k+ pages site.
- The program may sometimes stall for several reasons (a thread hangs, a page its trying to read is too long, etc). In that case, shut down the program and restart it.
- Doesn't account for the fact that disallowed URLs and META noindex,nofollow URLs accumulate PageRank.
- Doesn't drop duplicate URLs.
Updates
- 8/21/2007 - Fixed META robots parse bug.
Notes
- Make sure your internal links consistently refer to either non-www or www version, not both (I can name names here, but I won't).
Bug List
- Robots.txt isn't always parsed correctly, especially if you have Allow: statements, wild cards, and regexp.
- Some filetypes aren't recognized. If you see the tool stalling on a multimedia file, this is probably the cause. The recognized file types: avi, css, rdf, jpg, wmv, pdf, flv, mp3, mov, mpg, mpeg, m3u, zip, vbx, wmf, js, class, ppt, gif, png, doc.
- The damn thing is slooooow (well its not Googlebot and does more stuff in the background than Xenu .. if you wanna make it faster, shoot me an email)
Not sure how to use this Tool to Fix Supplemental Results Issues?
Read my blog post explaining in detail how you can use this tool to rewire your site's internal links and pull pages into the main index. I also wrote about how you can use this tool to implement Third Level Push.
Also a few basic internal link strategies which I found reading Dan Thies' SEOfastStart PDF:
- Third-Level Push (aka siloing): Nofollow links between second-tier pages (your category pages), so that they do not pass link juice to each other. This pushes more PageRank to the root level.
- Only pass juice back from third-tier pages (your product detail pages) to its parent category page. Nofollow links to other second-tier pages.
- For a lightened effect (if some second-tier pages take too much of a PageRank hit), link second-tier pages in pairs: link page A to B, C to D, E to F.
- To pass around more PageRank in the third-tier, link the third-tier pages up circularly: Link page A to B and C, B to C and D, C to D and F.
Use those tactics at your own risk.
Using PageRankBot tool, you can even go a few steps further by really defining exactly how much PageRank gets passed to a particular page. For example, you can push pagerank to a particular page temporarily to attract organic links, and then after its grabbed enough links, shift PageRanks to another page that requires attention.
Feedback & Support
Having problems? Contact me and I'll see what I can do.
Why the Hell did I write this in Java?
- Because I don't know either Java nor Visual C++, so to save time, I went with an easier language to learn. Ok, so it may not be nearly as fast as Xenu or GSiteCrawler. But hey, what do you want from me? :)
What made me want to blow hours writing this?
First, I wanted to confirm or deny Matt Cutts' claim that PageRank is the primary factor of supplemental results. Second, I wanted a tool that helped me visualize what goes on under the hood of a site. Third, what if there was a tool that empowered you instead of you continuing to feel you're at the mercy of Google? This tool is my attempt at fulfilling that what-if scenario.
Copyright 2006 SEO 4 FUN